Introduction
Large language models (LLMs) have emerged as powerful knowledge bases yet are increasingly limited by their static training data, leading to issues such as hallucinations and safety risks. While model editing through the locate-and-edit paradigm has proven a cost-effective alternative to retraining, current approaches face significant challenges. Early methods focused on structured knowledge triplets, while recent approaches like AnyEdit extend to unstructured editing through window-based strategies. However, these window-based autoregressive methods often disrupt the causal dependency between early memory updates and later output tokens.
In this work, we first theoretically analyze these limitations and then introduce Matryoshka Unstructured Knowledge Editing (µKE), a novel memory update mechanism that preserves such dependencies via a Matryoshka-style objective and adaptive loss coefficients. Unlike existing methods that optimize each memory shift independently, µKE ensures that early memory updates account for their influence on all downstream tokens, maintaining the natural causal structure of autoregressive generation while benefiting from multiple localized memory updates.
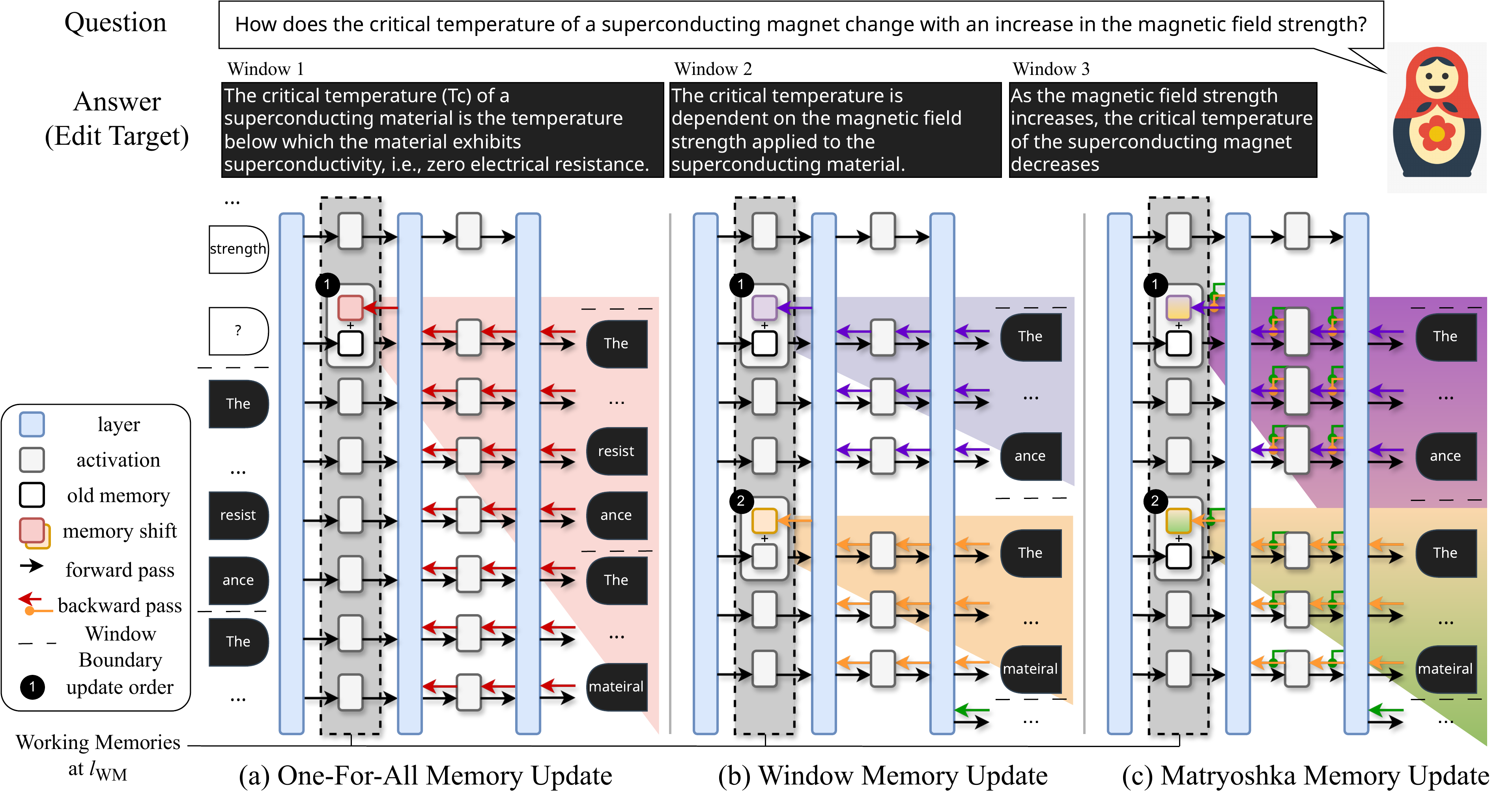
Figure 1: Comparison between different unstructured editing paradigms. (a) One-for-All updates one memory for the entire edit target. (b) Window-by-Window splits the target into windows but overlooks memory dependencies. (c) Our Matryoshka approach maintains proper dependency while benefiting from multiple memory shifts.
Empirical evaluations on two models across five benchmarks demonstrate that µKE improves edit efficacy by up to 12.33% over state-of-the-art methods, and remains robust when applied to diverse formatted edits, underscoring its potential for effective unstructured knowledge editing in LLMs.
Method
Key Innovation: Matryoshka-Style Memory Update
µKE introduces a Matryoshka-style objective that enables gradient flows from all latter tokens to former working memories during optimization. This approach treats each memory update as potentially contributing to all subsequent target tokens, maintaining proper causality.
Unlike window-based methods that optimize each memory shift independently, our Matryoshka objective ensures that early memory updates account for their influence on all downstream tokens. This preserves the natural causal structure of autoregressive generation while still benefiting from multiple localized memory updates.
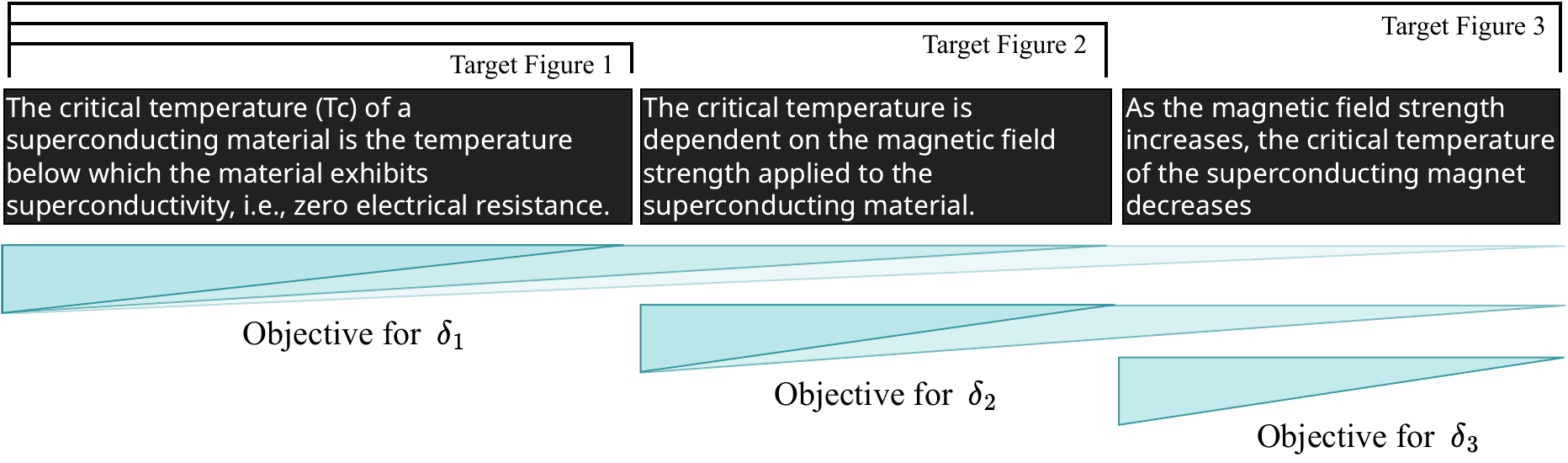
Figure 2: Matryoshka-style working memory update. For each δᵢ, the objective is a weighted sum of negative log-likelihood of all target figures starting from window i conditioned on previous contexts.
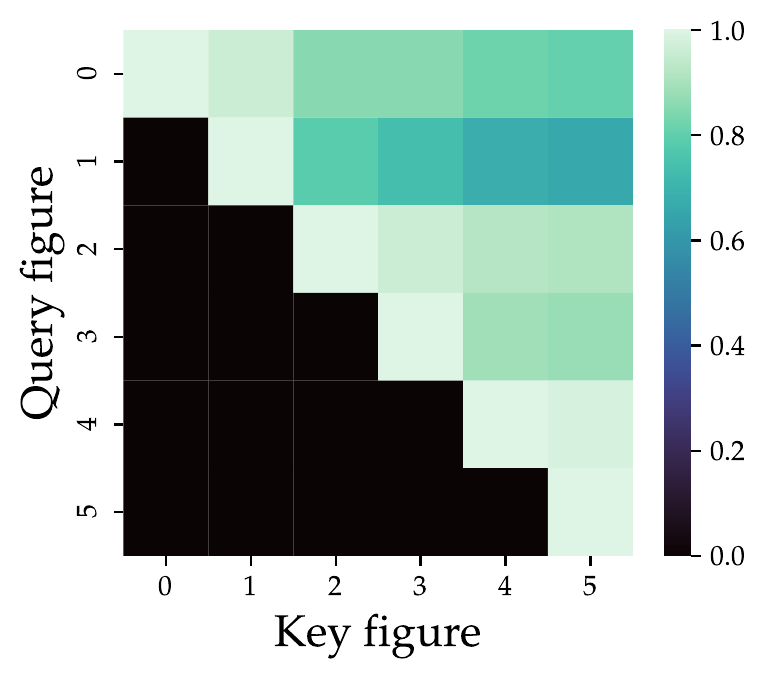
Figure 3: Affinities between target figures. The heatmap shows gradient affinity between different target segments, informing the adaptive coefficients for balanced optimization.
Adaptive Coefficients
We introduce adaptive coefficients informed by gradient affinity between target segments. This balances the contribution of intermediate terms and mitigates variance across different target lengths. The coefficients are dynamically computed based on the alignment between memory updates and their corresponding target segments, ensuring stable optimization across diverse editing scenarios.
Experimental Results
Experimental Setup
We comprehensively evaluate µKE on long-form knowledge editing across multiple dimensions:
Models Tested
- Llama3-8B-Instruct - Meta's instruction-tuned model with 8B parameters
- Qwen2.5-7B-Instruct - Alibaba's latest instruction-tuned model with 7B parameters
Benchmarks
- UnKEBench - Unstructured knowledge editing with long-form answers
- AKEW-CounterFact - Counterfactual editing for fact correction
- AKEW-MQuAKE - Multi-hop question answering edits
- EditEverything - Diverse domains (math, code, poetry, news, chemistry)
- SelfCheckGPT - Hallucination reduction evaluation
Evaluation Metrics
- BLEU - N-gram precision for lexical similarity
- BERTScore - Semantic similarity using BERT embeddings
- ROUGE-L - Longest common subsequence similarity
- Locality - Preservation of general capabilities (MMLU, IFEval)
UnKEBench Performance
Evaluated on 100+ long-form QA pairs with answers averaging 150+ tokens
AKEW-CounterFact
Counterfactual editing maintaining consistency across fact updates
Cross-Domain Robustness
Consistent improvements across math, code, poetry, news, and chemistry
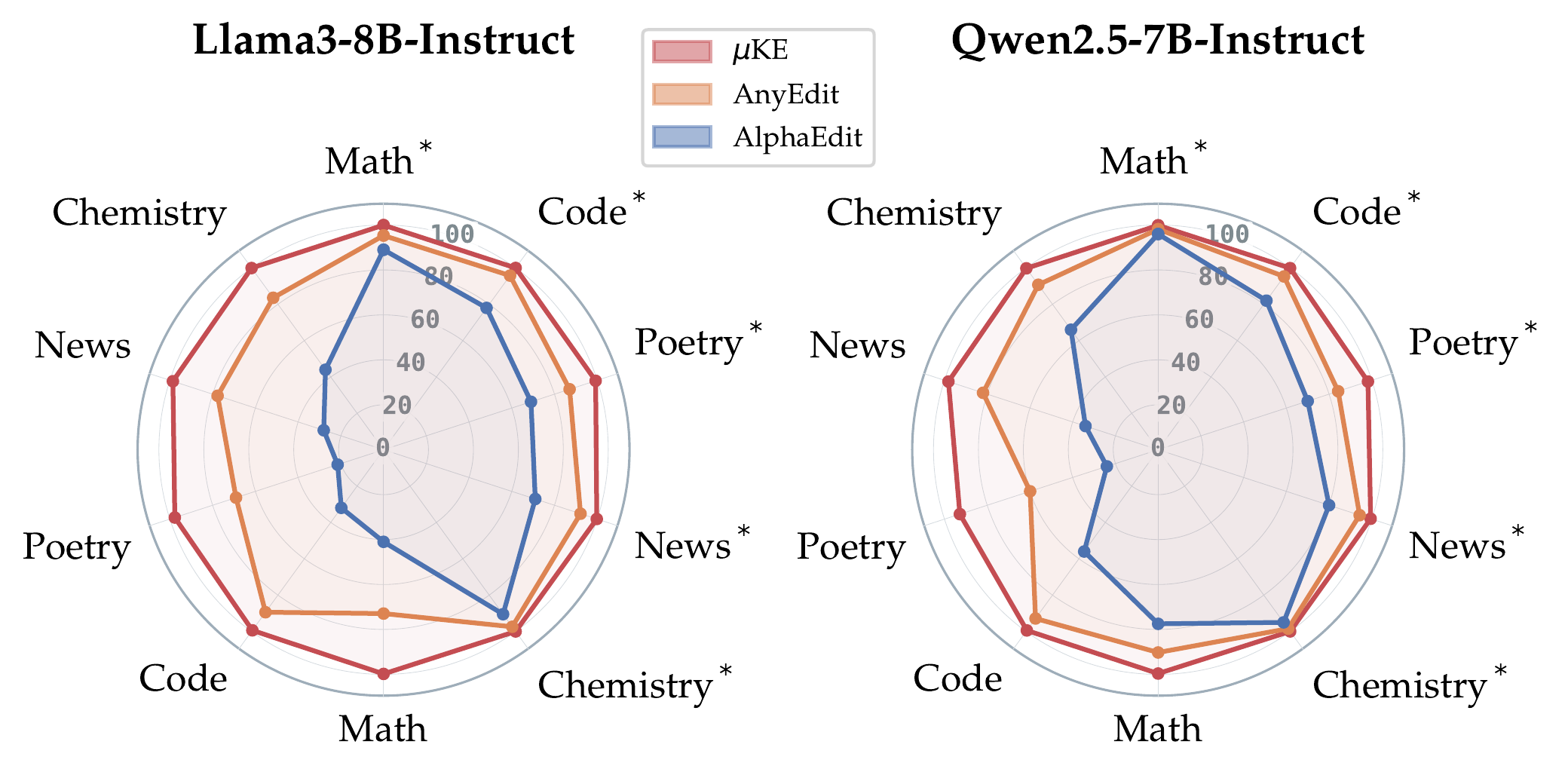
Figure 4: Performance on EditEverything benchmark. µKE demonstrates superior performance across diverse domains including mathematics, poetry, news, programming, and chemistry, showing consistent improvements over baseline methods.
Key Findings
- µKE improves edit efficacy by up to 12.33% in BLEU score over state-of-the-art AnyEdit
- Achieves near-perfect scores (>99.9%) on multiple benchmarks with the UnKE-based variant (µKE*)
- Maintains robust performance across diverse editing formats including math, code, poetry, news, and chemistry
- Preserves model's general capabilities on MMLU and IFEval benchmarks
- Shows superior generalization to paraphrased questions compared to baseline methods
- Performance remains stable across different target lengths unlike window-based methods
Performance Analysis
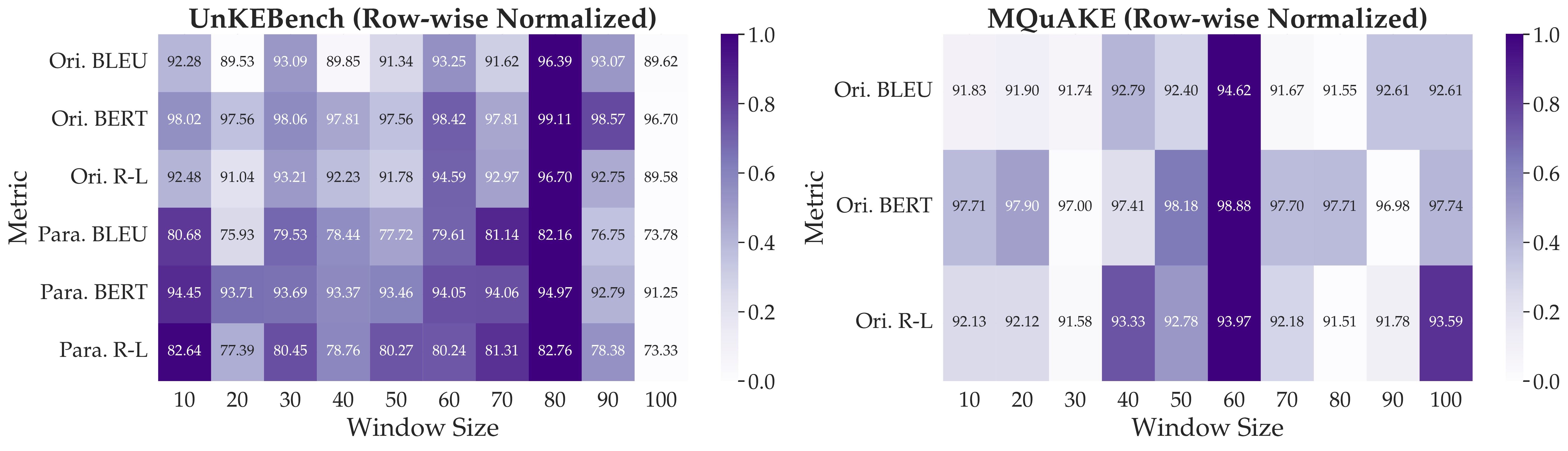
Figure 5: µKE performance with various window sizes. Performance is relatively insensitive to window size, with variations typically within 3% across all metrics. The optimal window size varies by dataset (best at 80 tokens for UnKEBench, 60 for MQuAKE).
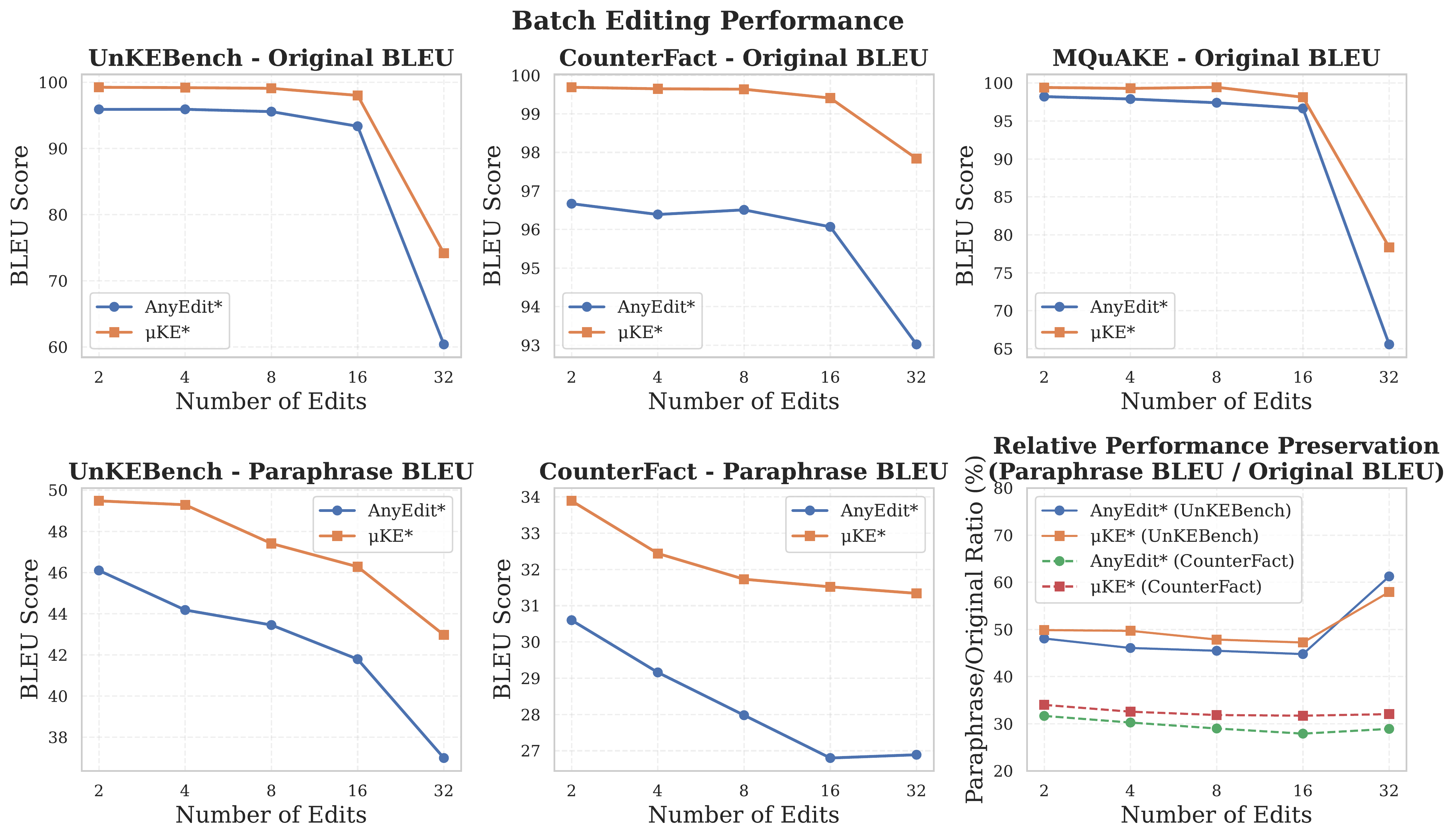
Figure 6: Batch editing performance. µKE consistently outperforms AnyEdit for different batch sizes, highlighting the significance of maintaining memory dependency for unstructured batch editing across UnKEBench, CounterFact, and MQuAKE benchmarks.
Citation
If you find our work useful, please cite:
@misc{su2025muke,
title={$\mu$KE: Matryoshka Unstructured Knowledge Editing of Large Language Models},
author={Su, Zian and Huang, Ziyang and Zhang, Kaiyuan and Zhang, Xiangyu},
year={2025},
eprint={2504.01196},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01196}
}